An Introduction to the Docker Ecosystem

Traditionally, developing an application and deploying it in a production environment hasn’t been easy. Development and production environments are often configured differently, which makes it difficult to resolve problems quickly when something was broken. A popular tool named Docker solves this problem by allowing developers to package their applications in a portable way without all of the hassles of a traditional system.
In this article, we’re going to look at the basic concepts of Docker: the way it works, the general workflow when using Docker, and the related terminology.
Hypervisors vs containerization
Development and production environments often differ in configuration and the software installed. In addition, different applications may have conflicting software requirements. These problems make deploying applications rather difficult. Developers did have a solution that somewhat eased the problem: a software that emulates a full computer, otherwise known as a “hypervisor”.
A hypervisor allows you to create a virtual machine(VM) into which you can install an operating system. You can install the necessary versions of software in them, and then you can run your application in it. In this way, all applications are isolated from one another. This eliminates conflicts and adds a level of fault tolerance: a bug in an application can, at most, affect the virtual machine it’s running on. Multiple applications can be run this way, and individual VMs can be packaged and deployed on other systems.
The diagram below shows multiple applications running on a single host in this way:

Unfortunately, emulating hardware takes up significant resources, making this method slow, inefficient and power hungry. In addition, a separate OS is installed inside each VM, which adds to this overhead. Fortunately, a lightweight form of virtualization, called “operating system level virtualization” or “containerization” solves this problem.
OS-level virtualization allows creating “containers” inside which applications can be run. The resources available to the base operating system are shared to applications running inside these containers. However, these applications can’t affect others that are running on the base system or on other containers. Implementations such as Docker also allow you to package these containers and run them on other systems. Thus, these systems provide the same benefits of virtualization while being very light on resources.
The diagram below illustrates how applications run inside containers:
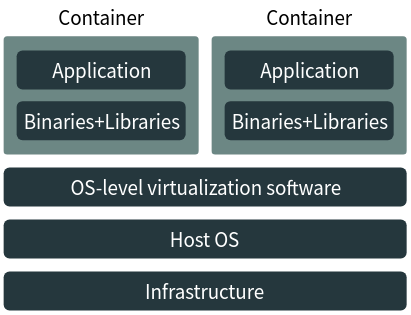
Although Docker has made containerization popular, various implementations have existed before it, although their goals have been usually different. For example, OpenVZ(Linux) allows for provisioning containers as virtual servers, while Sandboxie(Windows) allows you to create throwaway containers in which unsafe files can be opened.
Images
In Docker terminology, an “image” is a package that contains an application. Typically, an image includes executable files and shared libraries — all that’s needed for the application to run. This approach makes applications portable — they can be run on any system without needing to know anything about the application itself.
Typically, an image is created from a “Dockerfile”, which contains the steps needed to create an image. Each instruction in this file creates a “layer” in the file. When you change the Dockerfile and rebuild the image, only the changed layers are rebuilt, thus minimizing disk usage. Images can be also be created by persisting changes made to a container (discussed in the next section).
An image can also depend upon other images. As an example, a web application written in Python may depend upon an image containing a Python interpreter.
For easy distribution, images are stored in a registry. Once an image is “pushed” to it, you simply need to “pull” it on another system. The most popular public registry is Docker Hub, and there are many services which provide private registries. In addition, Docker has built-in functionality to run your own registry. If you don’t want to use a registry, you can “save” images as a tar archive and “import” them on another system.
Containers
An image is simply that — a packaged application. To run the application, you need to create a container. You can think of a container as the runnable instance of an image, with its own persistent file system and network access added to it. The container is completely isolated from the base system and the rest of the containers. However, you can configure it to access files or share ports from the base system if you need to.
After creating a container, you can “start” them. This executes the default command that’s been specified in the Dockerfile. However, you can also start up any other command. For example, you might want to inspect some files on an Ubuntu-based nginx container by running the bash shell in the image.
To make things easier, you can also “run” images directly, and Docker will automatically create a container for you. You can also stop, re-run and delete containers as and when you need.
When Docker attaches a persistent file system to the container, this also creates a layer. This forms the basis for another way of creating images. So, for example, you can take a base Ubuntu image, install your application in it, and then create an image off it. Docker takes the layers of the base image and that of the container to create a new image.
Services and orchestration
An application is usually dependent on a number of different components. For example, a video sharing application may be written in Python, which runs as a daemon. It persists data in a database server and depends on a component that transcodes video. When designing an application to run within Docker, it’s best to split up these components into individual containers. This form of design is often called “service oriented architecture”.
Separating services this way allows a specific component to be scaled up as per the requirements. Services built in this way should also preferably be independent of the host system. In addition, they should also provide consistent APIs for other services to use. This allows individual components to be changed, as long as the API through which they interact is kept the same.
A reasonably sized organization usually has multiple physical servers to run their applications. Docker allows you to scale services across multiple hosts through “orchestration”. It consists of a “scheduler” that selects nodes to run services. It also provides functionality to manage these clusters.
The Docker Engine provides a built-in “swarm mode” for this purpose, which we have described in the next section. In addition, there are other advanced orchestration tools, such as marathon and Kubernetes.
Docker’s swarm mode
Docker’s swarm mode consists of nodes participating in a cluster. A node is an instance of the Docker engine; thus, a single system can run one or more nodes. In most production environments, nodes are spread across many different systems.
These nodes are categorized into workers and managers. To deploy applications in a swarm, you submit a service definition to a manager. The manager node then dispatches various tasks out to workers. By default, services are load balanced among the different workers. You can also tell the manager to maintain a number of replicas across all the nodes available, or to run a single instance of the service on every node.
Despite its distributed nature, the service appears to be a single application to the consumer.
Networking and communication in Docker
A service oriented architecture makes communication necessary among the different services for coordination. Unlike some other containerization mechanisms, Docker sets up networking automatically. Specifically, it creates a network interface named docker0 on the host system, which allows it to create a virtual subnet from which IP addresses are allocated to individual containers. It also sets up the proper iptables rules so that inbound and outbound traffic are properly routed.
Many applications listen for inbound connections, and you can “expose” ports inside a container. You can also allow Docker to “publish” a port, which maps it to the host interface and makes it available to the outside world.
Docker also provides another mechanism known as “links” for configuring communication between containers. You simply need to specify the names of available services. Docker contains an embedded DNS server, and whenever an application in a container refers to the service through its name, it will be automatically resolved to the IP address at which it is available.
Service discovery
Apart from the concept of links we saw earlier, there are a variety of tools that allow for service discovery. Service discovery is a strategy that makes it easy to perform deployments. It does this by allowing containers to figure out details of the other services they need without any manual configuration by an administrator. Each service also registers itself to the discovery mechanism, so that other applications can find out about them.
The diagram below shows an example of an application finding its dependency through a discovery mechanism. App 1 registers itself with a discovery service on startup. App 2 has a dependency on App 1, so it first tries to locate App 1. When the discovery service replies with the details, it proceeds to connect to App 1.
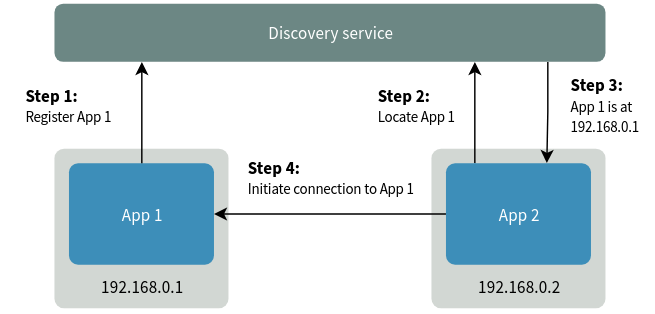
These discovery services are usually simple key-value based stores with an HTTP API to get and set values. These stores are also used to store configuration data for various services.
Some popular service discovery tools used with Docker are Consul, etcd and ZooKeeper.
Conclusion
Docker is a popular containerization technology that makes it easy to deploy applications. In this article, we’ve looked at a number of core concepts associated with Docker, and how services are deployed and run. More practical aspects of Docker such as creating images, managing containers and using registries will be explored in a later article.