Serverless Computing, Explained

The world is changing dynamically at a fast pace. The thing that is changing even faster is technology and the underlying architecture beneath it. In this article, we will dig into the depths of the new buzzword “Serverless Architecture”. We’ll find out what is really is, its advantages and disadvantages and whether you should consider moving your stack to serverless technology.
Drawbacks of traditional architecture
Before introducing any formal definitions to serverless architecture, we will look into the existing traditional architecture and find out its drawbacks.
Conventionally, applications were written and run in servers which are allocated fixed resources. Soon problems arose with sudden spikes of traffic as demands increased and the servers were not able to handle the enormous amount requests. To address these problems, came Platform as a Service (PaaS) in which providers offered scaling but it has its drawbacks compared to serverless architecture which we will discuss later in this article.
In a typical stack, most of the time the CPU remains idle, because the server is busy with networking and I/O requests. These drawbacks were handled by serverless architecture as we will see in the following sections.
What is serverless architecture?
Now you may be wondering whether the term " Serverless" means there are no servers involved. That is certainly not true. Serverless does involve servers, only the implementation and management is different. As discussed in the above section, traditional servers/compute instances have fixed resources, run all the time and need administrators to manage them. Serverless architectures , on the other hand, is run in compute instances that are event driven. What it basically means is that for each event or request to the server, a state is created and after the request is served, the state is automatically destroyed.
Unlike typical servers, serverless provisions are completely managed by the provider using automated systems that eliminate the need for server administrators. In serverless architecture, short-lived functions are invoked upon each request and the provider bills the client for running each individual function or business logic. Thus came the name Functions as a Service(FaaS). In most of the article, we will be referring serverless architecture as simply FaaS.
According to Wikipedia, the definition of serverless computing is:
Serverless Computing is a cloud computing execution model in which the cloud provider dynamically manages the allocation of machine resources, and bills based on the actual amount of resources consumed by an application, rather than billing based on pre-purchased units of capacity.
Some of the popular FaaS services are AWS Lambda, Azure Functions, Google Cloud Functions, IBM Bluemix OpenWhisk, webtask.io and hook.io.
FaaS vs Managed Servers
FaaS provisions allow running code without the need to manage the server system and server applications. So, what’s the difference between 3rd party managed servers and Faas? Both seem the same as you do not need to manage the server systems in either of them. The fundamental difference is that in FaaS, you also do not need to manage server applications which were not possible in typical systems.
Let’s take an example of a social media application to understand this. As users interact with the site, the application collects behavioural data and processes them in a dedicated server to learn more about the users and provide relevant content. Now, that server is only dedicated to machine learn those behavioural patterns. In the case of FaaS, it is replaced with functions that do not require that physical server to run and can be executed among other functions in a shared pool of resources.
There is another advantage to the FaaS architecture. You do not need to code your app to any particular framework or library. Any language can be used. What’s even more interesting is that two FaaS functions written in different languages can interact with each other. Multiple functions can be connected and chained together to implement reusable and composable systems.
Deployment and Scaling
Deploying FaaS applications is very easy. You need to upload the code to the provider in a compressed or executable format and it takes care of everything else. Later, to update the code, you just need to upload the newer version and initiate the update by calling an API.
Let’s come back to our social media application. There may be normal days where is traffic is average. But imagine a national holiday where the number of users may peak suddenly. This is very common in the case of e-commerce websites where the traffic may surge enormously in the event of a sale like Black Friday. In those cases, the server will not be able to serve so many requests and eventually crash. This can only be solved through scaling the server resources.
Perhaps the biggest benefit of FaaS is automatic scaling. As discussed earlier PaaS also provides scaling but the problem is that you need to estimate how much resources that you need and then provision them accordingly. This has problems since you may always over-estimate or under-estimate. With FaaS, you don’t even have to think about scaling. Just upload your code and forget the rest. Automatic horizontal scaling is completely managed by the provider and is totally elastic. If there’s a sudden spike in requests, the FaaS provider will handle it seamlessly without any extra configuration or management. So you can clearly see that there is no over or under estimation and accordingly cost benefits are huge.
In Backend as a Service (BaaS) which integrates into FaaS architecture, entire application components are provided as a service. For example, there are services like Kinvey which provides backend services like data storage, push notifications, analytics and more so that developers do not have to code their components. They just need to integrate those ready-made services in their apps. It saves development time and testing time and also reduces development costs.
The same benefits hold true against container technologies like Docker or Kubernetes. Container platforms do not offer automatic and transparent scaling solutions as of yet and serverless FaaS wins here too.
The problem with states
FaaS architecture is designed in such a way that individual functions are created upon each request and is destroyed after while. The state is not maintained only for a short while and then destroyed completely. So subsequent functions can not access the state and its data. So, FaaS functions are also called stateless functions. Now, this can be a problem as application architecture needs to be redesigned. Stateless functions can work for most of the use cases but not for all. Currently, it is handled by storing the state across multiple requests either with in-memory databases like Redis or simple object storages. But that is always slower than preserving states in cache or RAM in traditional architecture.
Recently Amazon announced a new service called AWS Step Functions. It comprises a state machine that provides a semi-persistent state that can be shared among multiple functions. You can learn more about AWS Step functions at Cloudacademy blog article.
Startup and Execution
Cold starting a function in serverless platform takes a considerable amount of time to load which can range from about a couple of milliseconds all the way up to a few minutes. This is certainly bad but happens only in a few set of conditions where the functions are accessed very infrequently. It can be overcome by a process called warming. A scheduled event is run for a fixed time interval (say every 5 minutes) and it invokes the functions so that it can trigger quickly in case of a real event.
Now let’s talk about execution. FaaS functions have a time limit till which they can be run. If they exceed it, they will be automatically killed. So long-lived processes cannot be created without changing the architecture of the application. The apps must be redesigned in which there are multiple coordinated functions that perform the task equivalent to a traditional long-lived function.
Efficiency
Most of the commercial servers that are used today in production environments are not utilized to their maximum extent. As a result, tonnes of kilowatts of power is wasted while the servers sit idle. This misutilization will come to an end once FaaS becomes mainstream. Serverless providers have large pools of servers in which billions of functions run parallel in a shared set of resources. So multiple clients can use the same hardware without any noticeable difference than that of a dedicated server.
The concept is explained in the following diagrams. Different applications have their dedicated servers in traditional architecture.
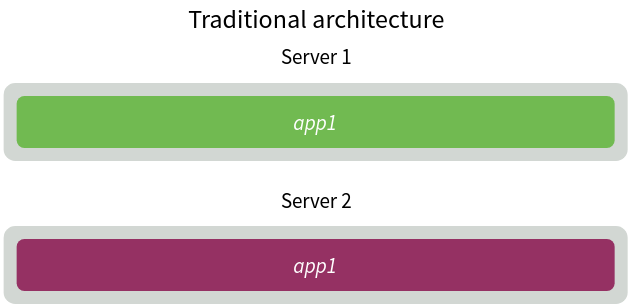
In the case of a serverless architecture, each server runs various functions of several apps. In the diagram below you can see one application has various functions and they can be run parallel on multiple servers. So, multiple functions of a single app are running simultaneously. Therefore, resource utilization is much more efficient.
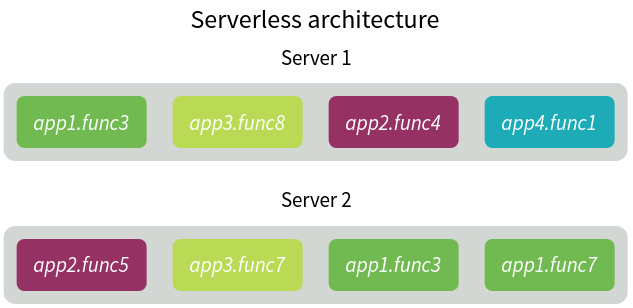
It even pays off by writing more efficient code which consumes fewer resources and runs faster since the provider bills the client based on the execution time of each function and the amount of resources it uses.
Vendor lock-in and control
Unfortunately, FaaS deployments also come with a major disadvantage: vendor-lock in. Different providers have different implementations of their serverless architectures. When you need to shift from one provider to another, you’ll have to port your code to the other provider, which could prove to be expensive. Most of the management is done by the provider which means you have very little control left over your system. There may also be security concerns in some cases where highly confidential information like financial transactions is involved.
Resources
There are a couple of good resources for developing FaaS applications. You should check out the Serverless Framework which is a great open-source CLI tool for building and deploying apps over various providers listed above.
The awesome-serverless GitHub repository is a nice resource which consists of everything like projects, blog posts, talks, plugins, services and much more all related to serverless architecture. It is a curated list of all the resources available which you should definitely have a look at.
We’ll now summarize the advantages and disadvantages of serverless computing.
Advantages
- Automatic Scaling: FaaS provides automatic horizontal scaling and handles sudden spikes easily.
- Reducing costs: Everything in serverless architecture is completely managed by the provider itself, eliminating the needs for system administration.
- Simple deployment: FaaS apps are very simple to deploy and update. All you need to do is to provide the compiled code and the platform takes care of the rest.
Disadvantages
- Startup and execution time: As discussed above startup and execution time of programs can be a problem in certain scenarios.
- State: Architectural redesign of code is necessary as states are not preserved.
- Vendor lock-in and control: Since FaaS deployments are highly coupled to the provider, you have very little control over your application and you’re usually locked in to a single provider.
Conclusion
It’s important to remember that Serverless Computing is very new and not yet mature. There are some use cases where the traditional architecture still fits best. If you think to move over to serverless, you should test your apps for FaaS first and make sure everything works perfectly. FaaS is a great revolution in cloud technology and should stabilize in the coming years.