RAID levels 0, 1, 4, 5, 6, 10 explained

As businesses grow, demand arises for more reliable infrastructure that can handle critical systems. An important component in stable and scalable infrastructure is proper memory management. In this article, we will look at RAID which is an abbreviation for R edundant A rray of I ndependent (or Inexpensive) D isks.
What is RAID?
RAID is a storage virtualization technology which is used to organise multiple drives into various arrangments to meet certain goals like redundancy, speed and capacity. RAID can be categorized into Software RAID and Hardware RAID. In software RAID, the memory architecture is managed by the operating system. In case of hardware RAID, there is a dedicated controller and processor present inside the disks that manage the memory. There are various raid levels as discussed below.
RAID 0
RAID 0 is based on data striping. A stream of data is divided into multiple segments or blocks and each of those blocks is stored on different disks. So, when the system wants to read that data, it can do so simultaneously from all the disks and join them together to reconstruct the entire data stream. The benefit of this is that the speed increases drastically for read and write operations. It is great for situations where performance is a priority over other aspects. Also, the total capacity of the entire volume is the sum of the capacities of the individual disks. The downside, as you may have already guessed it is that there is almost no redundancy. If one of the disks fails, the entire data becomes corrupt and worthless since it cannot be recreated anymore.
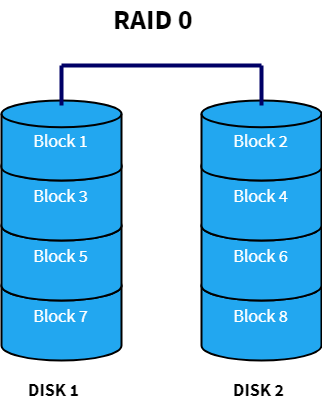
Advantages:
- Performance boost for read and write operations
- Space is not wasted as the entire volume of the individual disks are used up to store unique data
Disadvantages
- There is no redundancy/duplication of data. If one of the disks fails, the entire data is lost.
RAID 1
RAID 1 uses the concept of data mirroring. Data is mirrored or cloned to an identical set of disks so that if one of the disks fails, the other one can be used. It also improves read performance since different blocks of data can be accessed from all the disks simultaneously. This can be explained in the diagram below. A multi-threaded process can access Block 1 from Disk 1 and Block 2 from Disk 2 at once thereby increasing the read speed just like RAID 0. But unlike RAID 0, write performance is reduced since all the drives must be updated whenever new data is written. Another disadvantage is that space is wasted to duplicate the data thereby increasing the cost to storage ratio.
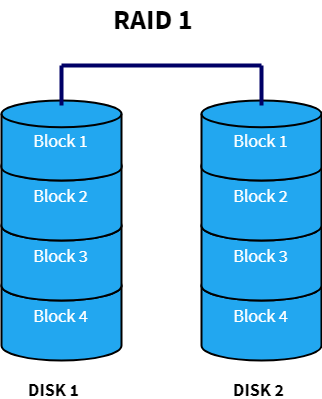
Advantages
- Data can be recovered in case of disk failure
- Increased performance for read operation
Disadvantages
- Slow write performance
- Space is wasted by duplicating data which increases the cost per unit memory
RAID 4
RAID 4 stripes the data across multiple disks just like RAID 0. In addition to that, it also stores parity information of all the disks in a separate dedicated disk to achieve redundancy. In the diagram below, Disk 4 serves as the parity disk having parity blocks Ap, Bp, Cp and Dp. So, if one of the disks fails, the data can be reconstructed using the parity information of that disk. Space is more efficiently used here when compared to RAID 1 since parity information uses way less space than mirroring the disk. The write performance becomes slow because all the parity information is written on a single disk which is a bottleneck. This problem is solved in RAID 5 as we will see next.
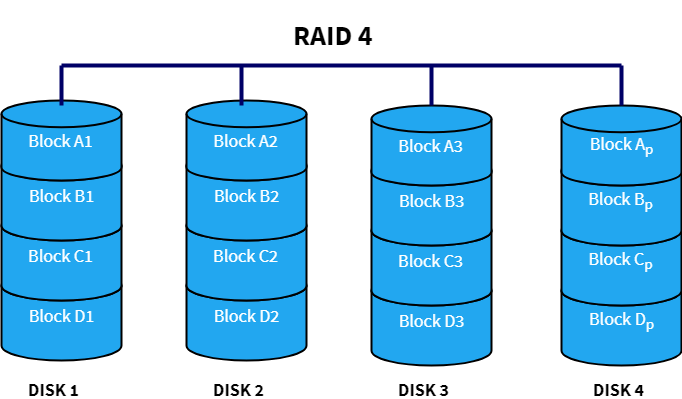
Advantages
- Efficient data redundancy in terms of cost per unit memory
- Performance boost for read operations due to data stripping
Disadvantages
- Write operation is slow
- If the dedicated parity disk fails, data redundancy is lost
RAID 5
RAID 5 is very similar to RAID 4, but here the parity information is distributed over all the disks instead of storing them in a dedicated disk. This has two benefits — First, there is no more a bottleneck as the parity stress evens out by using all the disks to store parity information and second, there is no possibility of losing data redundancy since one disk does not store all the parity information.
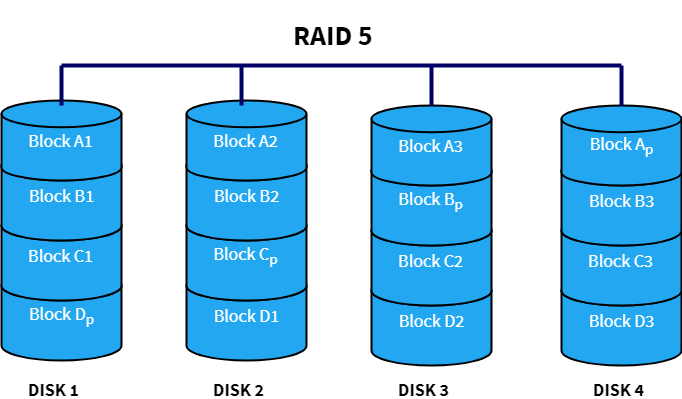
Advantages
- All the advantages of RAID 4 plus increased write speed and better data redundancy
Disadvantages
- Can only handle up to a single disk failure
RAID 6
RAID 6 uses double parity blocks to achieve better data redundancy than RAID 5. This increases the fault tolerance for upto two drive failures in the array. Each disk has two parity blocks which are stored on different disks across the array. RAID 6 is a very practical infrastructure for maintaining high availability systems.
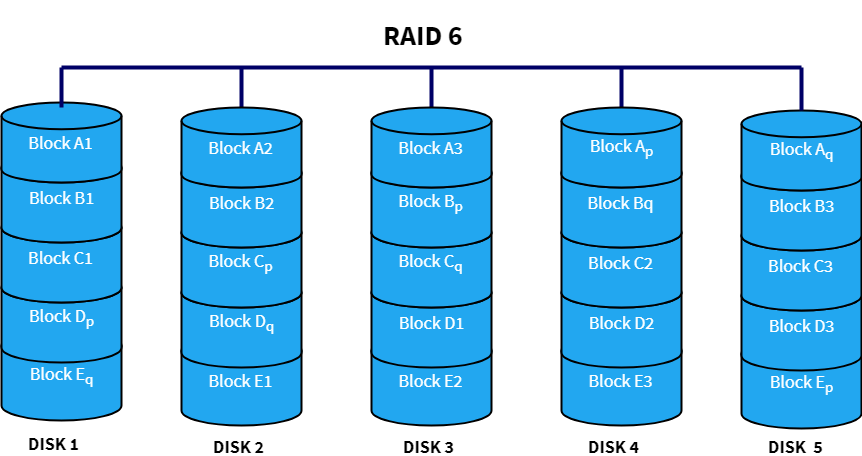
Advantages
- Better data redundancy. Can handle upto 2 failed drives
Disadvantages
- Large parity overhead
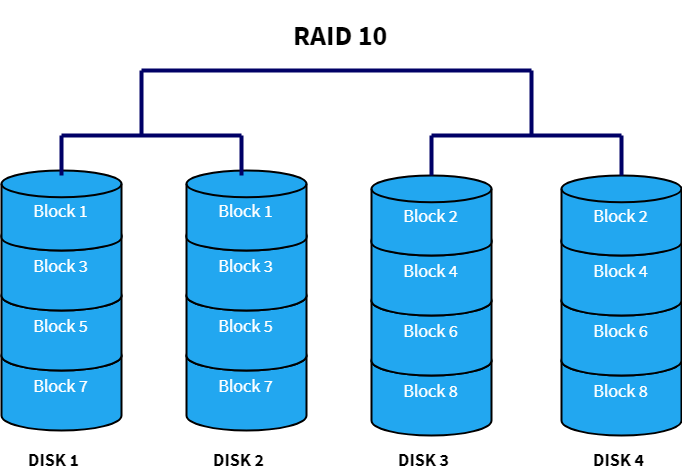
RAID 10 (RAID 1+0)
RAID 10 combines both RAID 1 and RAID 0 by layering them in opposite order. Sometimes, it is also called as “nested” or “hybrid” RAID. This is a “best of both worlds approach”, because it has the fast performance of RAID 0 and the redundancy of RAID 1. In this setup, multiple RAID 1 blocks are connected with each other to make it like RAID 0. It is used in cases where huge disk performance (greater than RAID 5 or 6) along with redundancy is required.
Advantages
- Very fast performance
- Redundancy and fault tolerance
Disadvantages
- Cost per unit memory is high since data is mirrored
RAID Implementation and Support
Many operating systems have built-in support for RAID. In Linux, there is a tool called mdadm which can be used to manage and monitor RAID devices. The entire setup and operation of mdadm have been explained in detail at the kernel wiki page. In addition, file systems such like ZFS, GPFS, Btrfs and XFS provide built-in support for RAID. On the hardware front, systems like Intel Matrix RAID has a dedicated drive controller chip which contains firmware and drivers to implement the RAID architecture.
Conclusion
Understanding the RAID levels is very crucial for developing storage infrastructure that meets the needs of the organisation. RAID has the capability to protect against disk failures and provide fast performance. However, it does not provide any means to protect against data corruption or implement security capabilities.